



微服务是一把双刃剑,在让我们提升开发效率的同时,也会让运维难度加大,尤其是 Serverless,其微服务器的粒度更小,随着数量的增长,缺乏配套设施的架构会变得一发不可收拾,而治理和运维的难度也随之呈现级数性增长。本次分享主要讨论如何对 Serverless 进行更有效的服务治理。本文由 MegaEase 创始人、腾讯云 TVP 陈皓在 Techo TVP 开发者峰会 ServerlessDays China 2021 上的演讲《Serverless 的服务治理》整理而成,向大家分享,本次分享完整视频请见文末。
今天带来的《Serverless 的服务治理》,听着一下子把 Serverless 变重了,但是能上生产线企业级的东西有时候就是这样。我们需要明白简单的东西背后一定不简单,就像我们家里拧开水龙头有自来水或者插上插座就有电,但后面供应自来水和电力的那套东西极其复杂。
为了说明这个复杂性,让我们先从 Serverless 的历史说起。从 2006 年始于 Zimiki,这是伦敦的一个公司,当时的 slogan 是 “Pay as you go”,听起来很美好,但在商业上极其失败,这个公司你们可能都没听说过,因为它在 2017 年就关闭了。然后,2008 年的时候, Google 的 App Engine 问世,它仅限于Python,包括具有 60 秒超时的 HTTP 函数,以及具有自己的超时的 Blob 存储区和数据存储区,但最终被 Google Cloud Platform 取代了。还有 PiCloud 平台,旨在通过三个操作来简化云计算,然而也失败了,在 2013 年被 Dropbox 收购,还有 dotCloud,Docker 公司前身,最终也是以失败告终,但是将 Docker 开源后又火了一把。国内各种 APP Engine 比如 TAE、SAE……那时候都在做,但惨淡经营,全部以失败告终。
2014 年,随着 AWS Lambda 函数式服务化的计算模型,在 2015 年再加上 API Gateway,让 Serverless 又卷土重来,配合上已有的云服务,大放异彩。而 Google 把内部的 Omega 系统的理念拿出来开源了Kubernetes,不但解决了环境部署问题,还解决了一整套的调度和编排和架构问题,在今天是相当火。有了 Kubernetes 的加持 ,2016 年是Google Cloud Functions, IBM Cloud Function, Azure Functions……2017 年是 Cloudflare CDN,随后Knative, OpenFaaS, Kubeless, Fn, OpenLambda, IronFuncitons, Fission, Apache OpenWhisk 等开源软件又让 Serverless 成为热门。

那是不是 Serverless 已经完全等同于 FaaS 了?其实这是有它的道理的。
首先是,我们的基础设施开始变得越来越完善了,就像我们今天的编程,程序员已经不关心内存怎么分配了,也不关心 TCP 网络包怎么弄了,只关心 RPC 的协议,他们中的大多数人已经基本不关心资源是怎么消耗的了,这表明我们的硬件资源、操作系统和编程语言已经做好了很多很多资源管理和调度的工作。当这些配套设施越来越强大的时候,我们就可以进入“资源无关”的视角了。这也就是所谓的 Serverless。
另外,我们势必会有各种定制化的需求,比如我想在文件存储服务 S3 上注入一些业务逻辑,这种需求还是很常见的,我举一个例子大家就明白了— Oracle 数据库的存储过程和触发器,有些时候我们在数据库上是否不单单只想存储数据,而是希望它能有一点点业务逻辑,所以数据库的存储过程、触发器,就是为了用户的定制化需求,想入侵标准化的基础设施而生的。同样,势必会有业务逻辑侵入你的云设施、云服务;为了应对这样的情况,使用 function/plugins 这样的形态是顺理成章的。这个情况跟今天的 FaaS 是非常类似的。
这种场景是非常合理的,而且技术的时机也没问题,因为我们基础设施越来越完善,不再关心系统管理,也不关心服务器运转、代码的部署和监控日志等,我们只关心怎样以最快的速度把代码变成 Service。

第三个维度是业务逻辑,基础设施、技术手段永远不可能降低业务逻辑的复杂度,业务逻辑复杂度不可能通过技术来降低,只能通过优化业务来降低。也就是说,你不要觉得通过微服务/Serverless/FaaS 就可以降低业务复杂度了,这不可能,试想,那么轻的 Function 怎么把厚重的业务逻辑放进去?如果只是一些简单的,那没问题,但是这个世界总是简单后就想变复杂,需求总是会一点点加起来的,复杂东西总是会有的,一旦这个东西复杂后我们怎么办?试想生产环境下,我们全部是玩微服务或者 Serverless 的话,今天的实例数可能要增加 1-2 个数量级,从十个变成一百个、一千个,怎么管理?
下面,让我们来看一下 Serverless 所面对的一些技术问题。
我们有没有想过这些问题:Serverless 如何进行服务发现?怎么进行健康检查?如何做灰度发布或A/B测试?有没有想过需要监控哪些指标?我们今天做的都是生死检查,那健康检查怎么监控?此外,Serverless 有两种,一种以工作流的方式编排,另一种以消息驱动的方式Event driven,甚至一个小 Serverless 直接调 RPC 库中的另外一个,调用链跟踪怎么做?或者业务流程跟踪,它们之间的依赖关系怎么管理?容错处理呢?SLA 如何保证?基础设施的 SL 永远不等于业务的 SLA……这些问题一来,就很麻烦了——我想说的是,我们如果想做一个 “Hello World”、做一个玩具,那很简单,怎么做都行;但如果要做生产线的、能够扩展的、能够进行工业化的,就很复杂了。

我们再看,这是 2019 年 AWS 的 Principal SDE 在国外的 Serverless 论坛上的一页 PPT,他用 “Serverless is dead” 做演讲标题,纯标题党,Serverless 并没有死,但他想用这个东西吸引大家:不要关心 Serverless 这个名字,而是要关心 Serverless 到底能干什么。Serverless 本质上是干什么的?这里提了几点,首先 Serverless 能够降低运维的难度;其次性价比高,它非常密切地关注成本和使用量,希望以非常低的成本让你得到更好的体验,无需买服务,它的成本会在直接买一个服务器的成本的 1-2 个数量级之下;然后开发人员可以做任何事情,他们可以变成运维人员、SRE,这也是 DevOps 的精髓——把 Dev 变为 Ops。余下的还有比如它可以处理很多 user case、安全、best practice 等,并且你无需关心这些。

接下来讲讲技术的发展,这是我个人总结出来的。过去云计算基本上是资源型的运维,即我是卖资源的,把软件也当成资源来卖,今天的云计算已经变成了一种应用服务,这是 Cloud Native 诞生的原因。为什么图中前面有 Google?他们是极其高阶的玩家。我先说背景:Google 在移动互联网时代差点被灭掉,但它做了安卓系统,如果不开源安卓操作系统,大家试想一下今天手机操作系统会被哪些公司霸占?肯定是苹果和微软,这两家长期在操作系统上耕耘,而且也有移动设备的操作系统,Google 是落后的,必须把安卓系统开源,伙同一大堆玩家去打击第一名和第二名,所以它做得很成功。这个套路还在继续,K8s 也开源了,但 Google 绝不是一个开源公司,死了两三百个产品都不会开源,它的开源就是为了阻击第一名后获得自己市场。
另外一个 Cloud 是 Google 提出来的,但是 Google Cloud 做得并不成功,甚至连微软都不及,所以它通过 Kubernetes 成立了云原生基金会 CNCF,CNCF 里的项目基本上来说是全开源的,跟之前的安卓的套路一模一样。他的目的就是让游戏规则改变,因为他如果走资源型的路肯定玩不转,所以游戏规则从资源型变成了服务和应用型,以开源的生态来做,然后去竞争。如果说在资源层面上有 K8s 作为缓冲,其实在哪家云厂商已经没什么意义了,所有的云厂商都可以,甚至自建私有云,而 Google 的 Cloud 天生继承了 K8s。
而我是很相信趋势一定是从资源型往服务型转移,所以今天我跟很多公司的运维同学讲,你们的 CMDB 还在做资源型已经落后了,一定要做服务型的,要管的是 Service 而非 Resource。
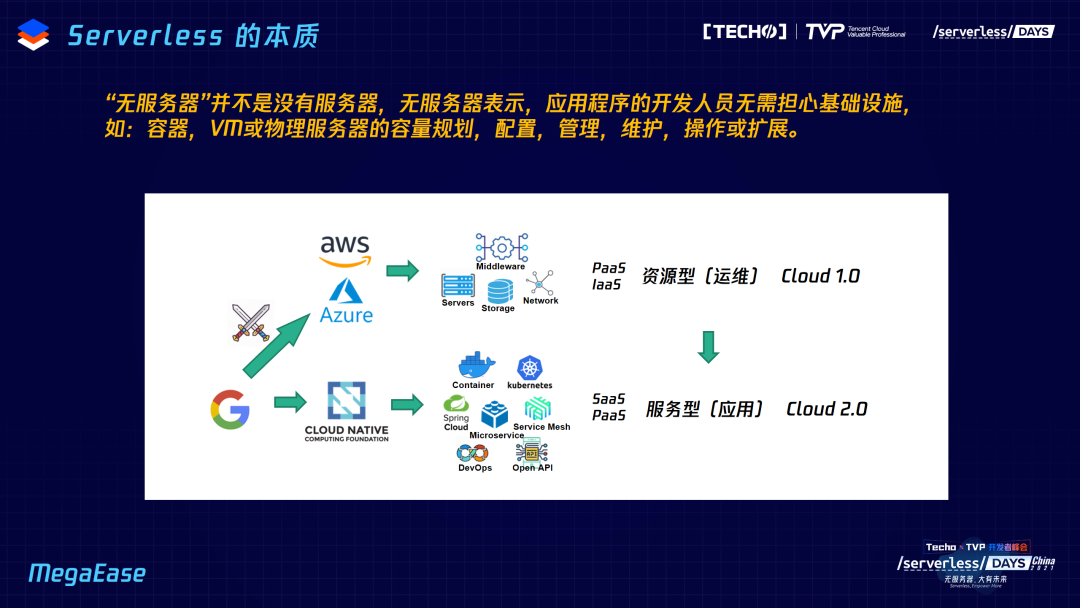
讲清了这个道理,我想说服务器并不是没有服务,无服务器表示应用程序的开发人员不关心基础设施,基础设施有很多东西:配置管理、维护操作,都不用关心,只关心怎么把代码以最快速度变成 Service。要做好这些,我认为有三个核心:
应用服务是一等公民,资源再也不是;
对外 API 是重中之重;
整体的 SLA 是头等大事;
意思是服务、API 还有 SLA,所有事情都应围绕这三个来做。如果都做好了,自然而然就能做出 Serverless。甚至是不是 Serverless 都无所谓,因为我们主要关心的是 Service 而不是 Resource。这意味着有没有提升我们的开发效率,可以更快地开发和上线?是不是可以有更高的性能和更好的稳定性、扩展性和安全性?有没有降低运维的成本?有没有很好地管理好成本和使用量?开发人员是否能更自然地融合到 DevOps/SRE 中?我们知道一个运维很多时候都是要开发人员参与的,所以能否通过这种 Serverless 的配套设施可以更好地让开发人员不需要被别人催,而是无缝地来做这个运维?
我个人觉得 Serverless 最基本的配套设施,包括底层资源的伸缩、编排,还有全栈的可观测性和服务治理。服务治理听着很重,SOA 才需要这些,但今天有那么几个还是需要的:服务注册发现、健康检查、配置、容错,最后还有流量;如果不管理好流量,流量在对外 API,也很难做。我们一个一个来说:

第一是可观测性,我见了很多公司做监控系统,出来就说“我们监控了五千个指标,那算啥,我们有十万个指标”,我觉得这些东西都没有意义,数据没有意义,把数据关联起来才有意义。数据不关联只是数据,数据关联以后才有信息,信息里面找到因果关系我们才能把它叫知识,科学就是一轮一轮做上几万次科学实验,进行数据收集,然后在数据中间找关联,把它联系起来,找因果关系,一旦找到一个因果关系就可以推出公式,公式就是知识,这个公式就可以拿去复制,我们所有的数学物理都是这么来的,所以一定要关联,关联了以后才可能会有更高层的因果关系的分析,不关联就不会有信息。所以我们要怎么关联?我们希望看到这样的关联图,从最前端的、直接服务于客户的 API,到后面的 Service,Service 用了哪些中间件,这些中间件又运作在哪个资源上?如果我们不能把这条链上的数据全部关联在一起,我觉得 Serverless 是做不出来的,运维是非常难的,假设我只关心某个 function,但它到底运行在哪个服务器上,它的调用链是什么,依赖的后台其它的云服务,或者中间件到底是什么?如果这些东西都不弄好的话,你就会觉得这个东西就像前面说的,只是个玩具。

另外一定要解决的是急诊和体检问题,快速故障定位和 SLA 的报告,容量分析,因为这里面波动肯定非常大,有很多数据要关联。做健康系统不复杂,但关联数据是很多公司并没有做的事情,为什么不做?因为很多公司的组织架构就是分裂的,组织架构里面必然有一群人是基础运维,另外一群人是应用运维,还有一群后端开发,还有前端手机端开发,各做各的健康系统;还使用了云服务,云服务有自己的监控。组织架构分裂,天生没有想关联、各干各的,这不是一个整体的设计,而 Serverless 更强调的是整体往下设计。
再看流量管理,其中有流量保护。大家可能听过节点着色,但没听过流量着色,它很有用。流量着色是一种灰度发布,比如一个用户发出请求,我在入口 API,给他打上一个标签,假设这是我的灰度用户,我就可以顺着服务调度的流量框架一直给到整个调用链的新版本,流量必须要着色,不然很难做灰度发布,或者蓝绿部署,A/B 测试更难。还有流量过滤,流量过滤是一种安全或者一种保护,你的 Serverless、Function 太多了,有时候需要做编排,需要调 ABCD 这四个事情才能做成一个,既可以聚合也可以编排,这都是流量网关要做的。接着是降级,满足自我保护;还有容错管理,对后端的负载,包括一些熔断,这是流量管理的特点,我们再来看服务治理。

服务注册发现,Serverless 服务启动以后怎么注册,怎么被发现?支持灰度的多版本怎么做?是 K8s 的 DNS 服务注册发现,还是要用比较传统的经典的 Java 技术栈的服务发现?然后是配置管理,CMDB 刚才讲过了,一定要看服务视角,而不是资源视角,CMDB 非常重要,但是一定是在服务,或者 API 视角。还有健康检查,到底怎么做?今天很多公司说健康检查是比较 low 的做法,看进程起不起、端口化在不在,这种叫生死检查,只有两个状态,宕机(死)还有 UP(生)。而健康是什么?健康是半死不活、亚健康,请求里面一些 ok 一些不 ok,一些快一些慢,这才是现实生活中的事情。K8s 的 liveness 和 readiness 两种探针,在实际应用当中是有问题的,因为它会重启,按道理来说服务有时候在不健康的时候也不能重启。应用的可观测性,吞吐量、响应时间、错误率也必须要看。

一般来说我们会有两种做法,一种以是 Mesh 的方式,一种是 SDK 的方式,SDK 有点侵入的意味,但因为有些是静态语言只能内嵌使用,为什么一定要内嵌?因为我一定要知道应用内部发生了什么事,要知道内部的一些响应时间。另一种 Mesh 的方式,现有的 Mesh 方式比如 Istio 是跨语言的,但它有很多小的问题,它的观测性并不完整,尤其不能嵌入到应用程序内部。JavaAgent 是无侵入式观测应用内部的,如果在 Java 系这是非常好的手段,再配合边车,可以很容易做到无侵入式的手段,把监控和服务治理包括流量管理全部做在边车和 Java Agent 里,Sidecar 管外、Java Agent 管内,流量和服务治理交给 Sidecar。这两者都可以,我觉得有 K8s,Mesh 的这种方式会更好。
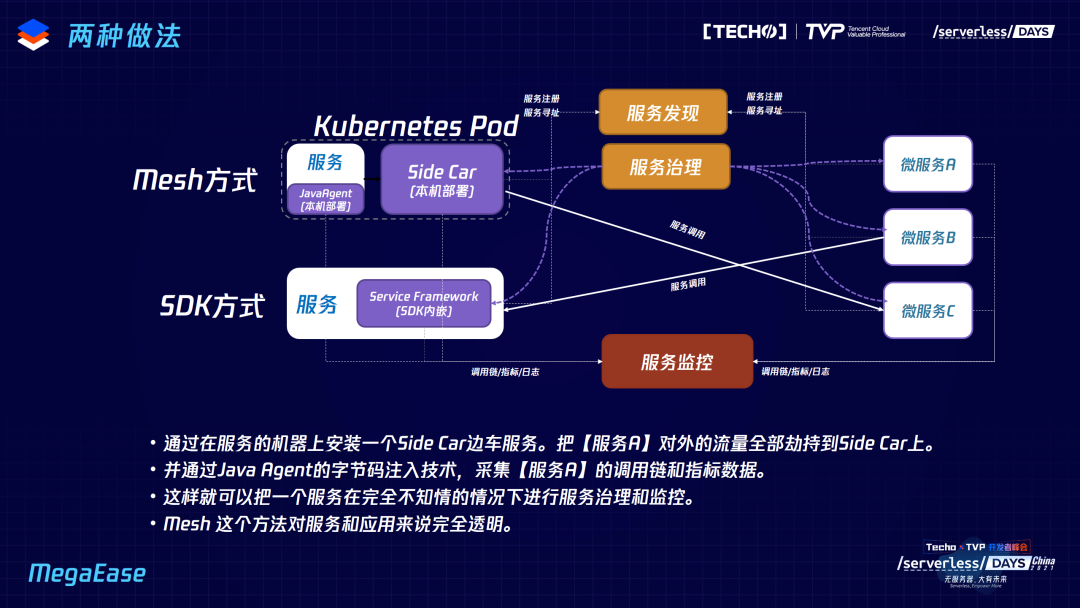
由于时间有限,我不展开讲 Istio 里面有哪些问题,只大概讲方法论。我们希望是下图中的这个样子:

左边是传统的东西,很简单,怎么一下子变成这种样子?好像很复杂,但是如果左边服务数量是一百个,你会觉得这边东西很合理,就不会觉得是过度设计。我想说的是,左边是 Spring Cloud 一个小的宠物医院的演示应用,我们有一个像这种 Mesh Ingress 的管住流量,它会把这些流量转到 sidecar 上,通过应用上的 JavaAgent 保证灰色流量可以被跟踪,这样就可以进行整个调用链内的灰度转发。另外,我们的控制台服务治理,会帮你自动注册,Service 可以完全不关心这些,我们配套设施全部以这种方式来建设,就可以真正做到比较完美的 Serverless。但是今天的 Serverless Mesh 做得非常有问题,它要把这一套服务治理扔掉改成另外一套,你就会觉得有点别扭。我们正在做一套完全兼容现有 Java 体系的 Serverless 的方式。欢迎关注我们的开源项目,谢谢大家。
陈皓,MegaEase 创始人、腾讯云 TVP,网名 @左耳朵耗子,资深程序员,酷壳 coolshell.cn 博主。前亚马逊高级研发经理,阿里巴巴资深架构师技术总监。目前创业,公司 MegaEase 创始人,致力于为企业用户提供一个可以不改一行代码就可以提高系统性能和稳定性的产品,即 Cloud Native 和微服务调度。






