



在阅读本文之前,需要读者对 Serverless 概念有一定的了解,如果你还不知道什么是 Serverless,也可以先阅读本系列之前的相关文章。笔者在之前的几篇文章,重点讲解了很多关于如何 Serverless 化传统服务和 Serverless 实战经验,比如如何实现一个后台管理系统。但是在实际开发过程中,我们不仅要考虑如何将自己的服务迁移到 Serverless 架构上,还需要了解 Serverless 架构相对于传统架构的区别,这样才能够在实际工作中,开发出更加高效稳定的服务。本章是笔者在 2 年的 Serverless 研发过程中,总结出来的认为比较重要的几点知识经验,希望对读者有所帮助。
本系列文章分为理论和实践两部分,理论部分会介绍一些 Serverless 相关概念介绍,然后在理论部分的基础上总结出一些实际项目开发中的一些开发建议。
本文主要内容:
本文以 Knative 为例,介绍 Serverless 是如何实现自动扩缩容的。
Knative 是谷歌开源的 Serverless 架构方案,构建在 Kubernetes 的基础上,旨在为构建和部署 Serverless 架构和基于事件驱动的应用程序提供了一致的标准模式
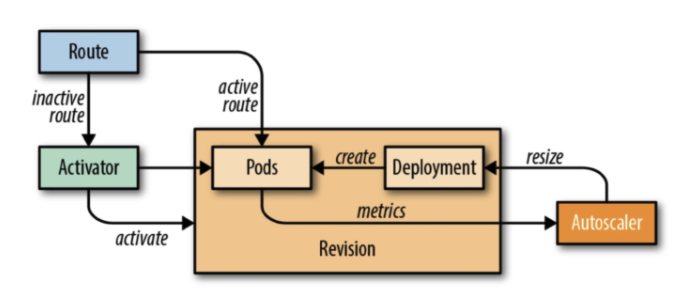
Knative 自己实现了一个 KPA(Knative Pod Autoscaler) 算法,用于自动扩缩容。KPA 算法的基本思想是,系统依据当前监控到的流量(并发请求数)来自动扩缩容。简单计算公式就是:
期望的实例数 = 当前并发请求数 / 实例支持并发数
举个 ,系统检测到当前一共有 100 个并发请求,单个实例支持并发数为 10,那么期望的实例数就是 100 / 10 = 10。如果当前系统可用的实例数为 1,那么系统就会自动新增 9 个实例,直到达到期望实例数 10。在这 9 个实例准备好前,Knative 会将请求缓存到 Activator,直到扩容完成(9 个实例准备好)后再转发到 FaaS(函数代码执行处理请求),而等待实例准备好的过程就是人们常说的 冷启动,接下来我们来聊聊冷启动。
注:实际上,云厂商为了减少冷启动,会根据优化规则和算法分配更多的实例数量,比如实际扩容的实例数量 = 1.2 * 期望的实例数,这样下个检测周期到来时,即使并发请求为 120,当前活跃实例数也是够用的,这个后面也会讲到。
众所周知,Serverless 平台为开发者提供了多样化和便利的代码运行环境,在开发过程中,开发者可以不需要关心代码运行环境的准备,因为 FaaS 在运行时,Serverless 平台已经帮助我们准备好了,但是 Serverless 容器实例的启动并不是瞬时完成的,它是需要时间准备的,实例启动过程大致可以分为四个阶段:
下载代码 -> 启动实例 -> 初始化代码(加载代码和依赖) -> 执行函数
注:镜像方式部署的函数的第一步是同步镜像。
冷启动的过程就是包含以上全部四个步骤,而当容器准备好后,在不需要扩容的前提下,函数再次执行,就不会经历前面三个步骤,而是直接执行函数,这就是所谓的 热启动。
通常冷启动的时间是百毫秒级,热启动由于省去了前三个步骤,时间通常是毫秒级。所以我们应该尽可能的减少冷启动。优化函数的冷启动的方法,主要有两个维度:冷启动的时间和冷启动的概率,接下来将从两个维度分别讲解。
减少冷启动的概率主要有两个方法:实例复用和实例预热。
函数代码执行结束的实例并不会不会立马回收,而是会从活跃状态(Active)变为待命状态(Reserve),等待下一个请求的到来。处在待命状态的实例会有一个待命时长(可配置,一般默认是 30 分钟),如果在这期间没有请求需要处理,实例就会被回收。如果有请求需要处理,实例就会重新进入活跃状态然后处理请求,从而达到实例复用的目的。
但是如果设置待命时长太长,待命实例就会长期得不到回收,从而造成资源浪费,这会对云厂商成本产生很大影响。所以各个云厂商会根据各自产品情况和优化策略,尝试设置一个最优值。
实例预热可以分为两种类型:被动预热和主动预热。所谓被动或者主动,通常是指是否是用户主动的行为。
被动预热就是在进行扩容时,会基于实际情况扩容大于当前期望的实例数量,具体数量的比例是云厂商自己决定的。
主动预热是指开发者依赖 Serverless 平台提供预留实例的能力,主动配置预留实例的数量,主动配置的预留实例数量将不会被释放。这样当请求到来时,已经预留好的实例可以直接提供服务,可以有效避免冷启动的概率。
前面提到过,如果一直保持实例不被回收,会大大增加 Serverless 的成本,所以云厂商针对预留实例收取一定的费用,所以需要开发者根据自身服务特点,评估是否需要预留实例和预留多少实例数量。
以上优化冷启动概率的方法都是需要依赖 Serverless 平台提供的能力,就算是主动预热也是需要平台支持预留实例功能后,开发者才能配置。实际上,我们还可以通过主动调用函数来实现实例的预热,利用 实例空闲后隔一段时间才会被回收 的特点,可以通过定时触发函数执行的方法,来实现实例预热。
比如我们在创建 Serverless 函数(以下简称 FaaS) 时,同时还可以给它配置上定时触发器(通常 FaaS 可以配置多种类型的触发器,定时触发器是其中一种),这个触发器可以每隔 5 分钟(可配置)触发一次 FaaS 执行,这样就可以实现定时预热。而且还可以根据 FaaS 服务的情况,设置多个定时触发器,从而应对不同的并发场景。
但是 FaaS 是按照自身运行时使用的内存和时间收费的,设置定时触发运行,是会产生费用的,所以我们也不能随便乱用。当然还需要在 FaaS 代码中,通过判断获取的事件类型为定时触发器类型,做特殊处理,比如尽快返回结果,以便让函数能够以更短的时间运行,从而减少费用。
注:云厂商一般会限制函数可配置的触发器个数。
针对冷启动的时间,主要是优化前三个步骤:下载代码、启动实例、初始化代码。其中除了 启动实例 时间依赖平台底层的优化外,下载代码 和 初始化代码是我们开发者可掌控的,毕竟代码是我们自己写的。
在相同的网络环境下,下载代码 耗费时间,取决于 FaaS 代码的体积,而且代码体积越大,下载时间越长。
很多开发者在刚开始接触 Serverless 开发时,会将代码全量上传部署到 FaaS,于是部署到 FaaS 的代码包括了很多不必要的代码和依赖,这样就会导致 FaaS 代码比实际的业务代码体积大很多,于是 下载代码 过程就会变长,自然冷启动时间也会变长。
这里以 Express.js 应用为例,在本地开发 Express.js 项目时,会安装很多依赖包到 node_modules 目录,其中包括生产环境依赖(dependencies)和开发环境依赖 (devDependencies),这两种依赖都是在本地开发时必须的(比如 Jest 单元测试模块),但是在生产环境中,是不需要开发环境的依赖的。
很多开发者为了省事,部署时,都是直接执行 npm install 命令,将这两种依赖同时安装,大多数时候项目的开发环境依赖的体积是大于生产环境依赖的,这就直接导致 FaaS 代码体积过大。实际上在部署到 FaaS 前,可以通过执行 npm install --production 命令来指定只安装生产环境依赖就可以了,这样可以大大减少部署后的 FaaS 代码体积。
另外,有些项目是需要编译的,比如基于 TypeScript 开发的项目,我们可以还可以引入打包工具(比如 Webpack,Rollup),将项目代码打包压缩,甚至可以借助打包工具的 Tree shaking 技术,将不需要的代码删除,都可以有效减少 FaaS 代码体积。
先来看一张关于 FaaS 代码依赖模块数对冷启动时间的影响的测试结果(图片来自文章 《Serverless: Cold Start War》):
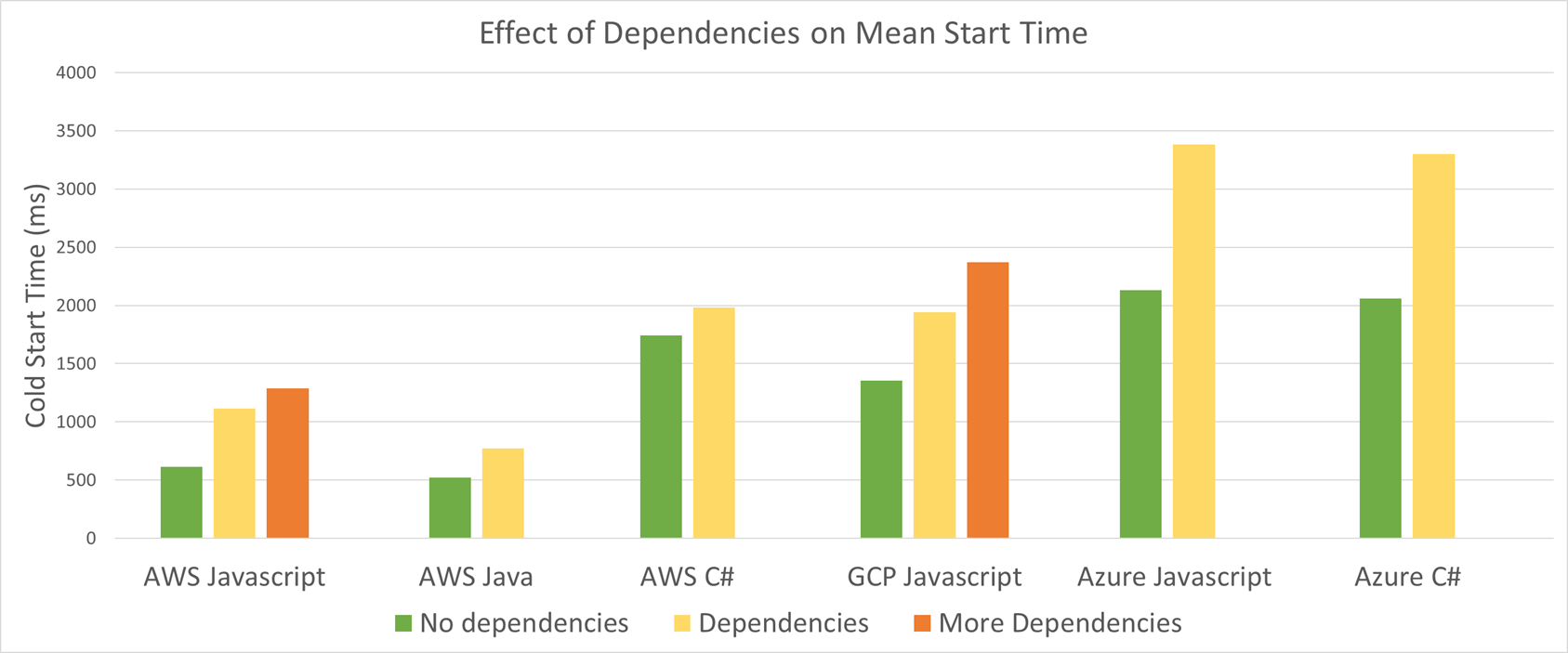
通过上图可以看出,依赖数量越多,冷启动时间越长,这是因为依赖包越多,代码体积会越大,下载代码 步骤的时间就会越长,同时 初始化代码 步骤所需要的时间也会越长。
所以减少不必要的依赖变得很有必要。其实在讲 优化代码体积 时,已经提到如何减少项目依赖。除了以上提到的方法外,开发者还可以在编写业务代码时,尽量减少不必要的模块依赖的引入。
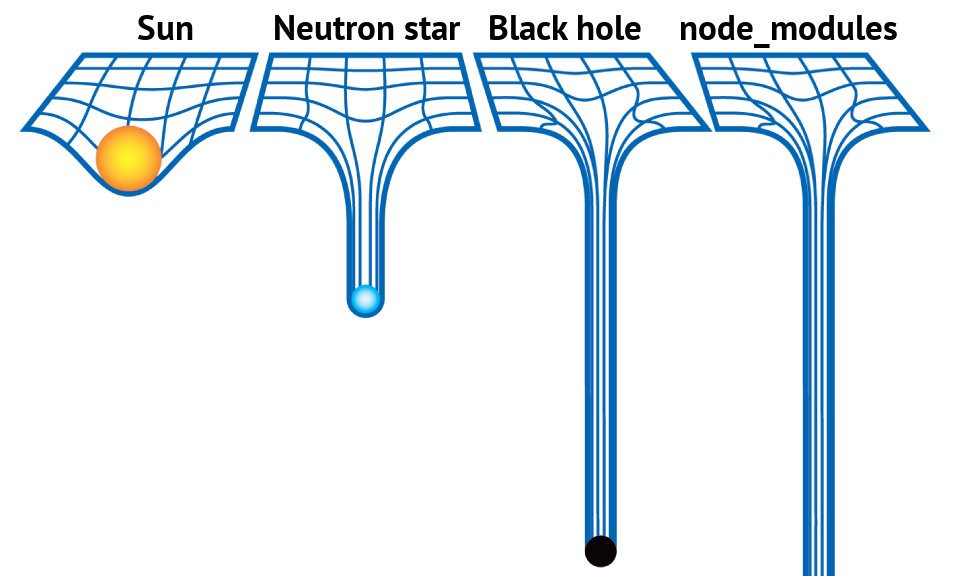
比如在前端开发中,项目的依赖目录 node_modules 像黑洞一样,深不可见,动不动就几百兆,甚至上 G 的大小,这是因为最初 npm 在安装模块时是树状结构,每个第三方模块都会将各自的依赖安装到各自的目录的 node_modules 中,这就导致如果不同的第三方模块依赖同一个模块时,就会重复安装到各自的 node_modules 目录。后来 npm 针对树状依赖结构进行了优化,改成了扁平结构,但是当依赖的同一个第三方模块版本不一样时,还是会存在重复安装的情况。而且开源社区的第三方模块质量层次不齐,有时一个简单的类型判断就需要通过安装第三方模块来实现,而且很多时候,我们只是用到了某个模块的很小一部分功能。
在开发项目时,我们应该多思考下,如果是某个简单功能,是不是可以自己开发实现,而不是在遇到问题时,总是想着使用开源的第三方模块来解决。作为一名程序员自己实现会花费更多时间,但是更快的提升自己,同时也能有效减少不必要的模块依赖的引入。
笔者在开发一些 Serverless 后端服务时,经常面临一个函数粒度问题:使用一个函数还是多个函数?
目前 Serverless 平台对传统 Web 服务提供了良好的支持,而且也提供了非常便利的迁移方法,比如腾讯云的 Serverless Components 解决方案、AWS 的 SAM 以及阿里云的 Serverless Devs ,它们都可以通过 YAML 配置的方式,快速便捷的将基于 Web 框架的服务部署到 FaaS 上。
但它们都是将整个 Web 服务部署到同一个函数里,这样可能会存在以下问题:
基于微服务拆分原则进行拆分后,还需要考虑服务中需要长时间运算或者大内存的接口,因为 FaaS 的收费标准就是每次执行的时长和使用内存大小,如果不进行拆分,服务函数的内存配置就需要按照大内存来配置,这就直接导致整体成本的上升。所以针对这种特殊的服务接口,我们应尽量能拆分成单独的函数进行处理。
超过云厂商 FaaS 的代码体积限制的 Web 服务(前提是已经进行了代码体积和依赖优化),如果想要部署到 FaaS 上,必须进行服务拆分的。
所以解决以上两个问题的方法就是拆分服务,至于如何拆分服务是软件开发中一直都存在的热门话题,本文就不深入探讨了,服务的拆分可以参考微服务拆分之道。
在选择函数类型前,我们先来了解下,截止目前为止,Serverless 平台支持的几种函数类型。
最开始的 FaaS 的运行方式都是事件类型,通过触发器触发事件,然后通过 FaaS 函数来处理事件。传统的 Web 服务入股偶需要迁移到事件函数,就需要在函数入口文件对 API 网关触发器事件进行转化,相关文章可以阅读 《如何将 Web 框架迁移到 Serverless》。流程图如下:
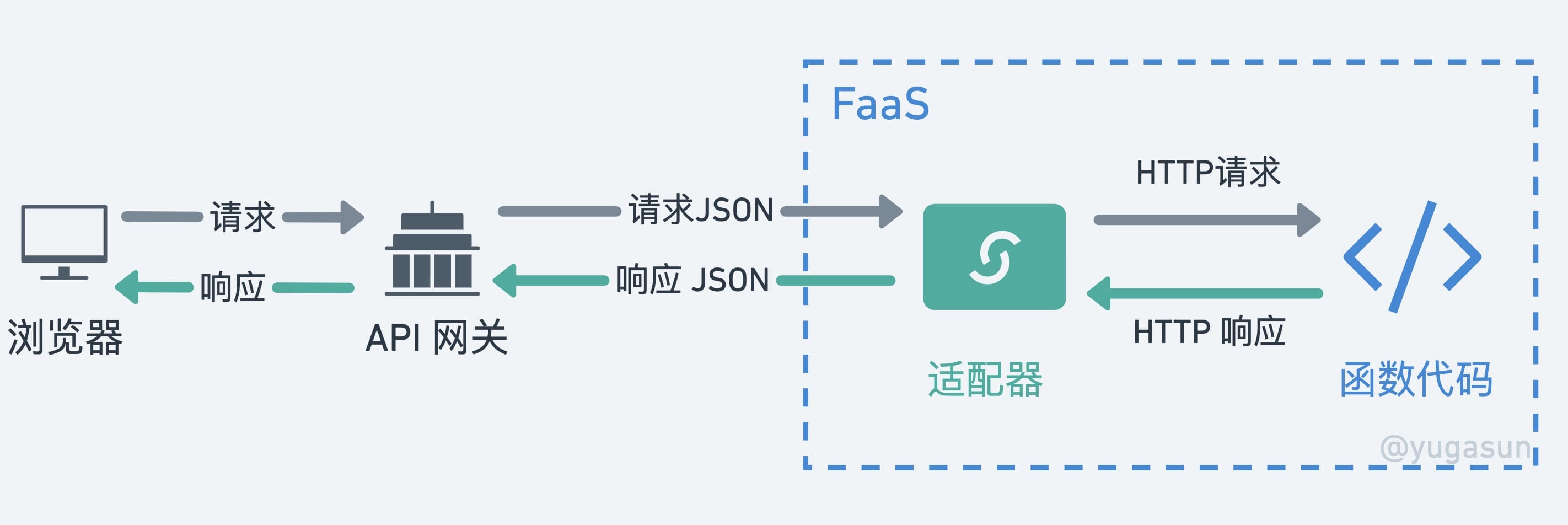
这种架构有个缺陷,就是针对每次请求,都需要经历适配层的转化,这会增加请求时延。由于 API 网关和函数之间是通过 JSON 结构体交换信息的,所以不支持原生文件类型传输,如果要传输文件类型,就需要在 API 网关侧,对文件类型进行编码(比如 Base64),然后在函数侧解码。
腾讯云官方介绍事件函数。
为了弥补事件类型函数的缺点,云厂商针对 Web 专门推出了 Web 类型(腾讯云叫 Web 类型,阿里云叫 HTTP 类型)的函数,通过 API 网关与 FaaS 的 HTTP 直通互连,开发者在迁移 Web 服务到 FaaS 上时,不再需要添加适配层代码来对 JSON 进行转化,从而缩短了实际请求链路,相对于事件函数具备更好的 Web 服务性能,而且开发者也不再需要进行入口文件改造,只需要按照传统 Web 应用开发方式,通过监听端口启动服务就行。可参考腾讯云官方介绍Web 函数。
更加详细的参数对比,可参考文章 《再探 Web Function - 用数据阐释优势》
基于代码部署的函数,它们依赖的执行环境都是云厂商预先提供的,这样就有个问题:针对一些特殊业务需求,特别是一些视频处理相关的函数,需要系统额外安装底层库来支持(虽然预装环境已经支持了大多数底层依赖,但是还是没法满足),但是开发者是没法自定义安装这些依赖到云厂商提供的运行环境的。
为了应对自定义运行环境的需求,云厂商提供了基于用户自定义镜像部署的 FaaS(这里只是部署方式的改变,但是 FaaS 类型依然只有事件类型和 HTTP 类型)。有了自定义镜像的部署方式,一些依赖底层库的应用就可以非常方便的部署到 FaaS 了。
虽然镜像部署方式非常方便,但是它有个缺点:大多数情况下,冷启动时间会比较长。为什么说大多数情况下呢,因为大多数情况下镜像比代码包的体积大,所以在冷启动时,拉取镜像的时间会比代码的方式慢很多,从而导致冷启动时间变长。当然镜像体积也可以优化,比如 Node.js 应用的基础镜像可以优化到几十兆,但是如果是轻量级的 Node.js 应用,而且不需要特定的依赖(比如 Puppeteer、TensorFlow、FFmpeg...),那么我们也就没有必要使用镜像方式部署了,使用代码方式部署会更加方便。
从字面上就可以看出两种 FaaS 类型的特点,事件类型更加适合事件驱动的业务场景,比如视频流处理,Kafka 消息订阅处理等,而 HTTP 类型更加专注于 Web 应用场景。至于代码部署方式,笔者还是主要推荐代码方式部署,除非是不得不定制化运行环境,才会使用镜像方式部署,毕竟镜像方式还依赖镜像服务,而企业版容器镜像服务(云厂商不提供个人版 SLA 保障)还是很昂贵的,并且镜像部署的冷启动时间也比较长。
开发者可根据个人需求,来灵活选择自己 FaaS 类型和部署方式,以上分析仅供参考。






